
Kapitel 1: Ein erster Überblick
Die BHt-Datenbank1 bietet dem Nutzer unter "Bücher" einen Zugang zum Text und zu den morphologischen und syntaktischen Daten, unter „Suche“ eine Möglichkeit einfache wie komplexe Suchabfragen vorest nur zur Wortebene durchzuführen.
Mit Klick auf "Bücher" erhält man eine Übersicht über sämtliche Bücher der hebräischen Bibel, zusätzlich Jesus Sirach.2 Von dort gelangt man zu den einzelnen Kapiteln. Für Gen 1,1-3 beispielsweise erhält man folgendes Bild:
Der Text wird syntaktisch gegliedert, die Transkription gibt die morphologische Struktur des Althebräischen wieder, jenseits der tiberischen Masora.3 Auf diese Weise werden beispielsweise Nominalformen sichtbar, wie sie in den Grammatiken behandelt werden, etwa QaTL als ʾarṣ für אֶרֶץ "Erde":
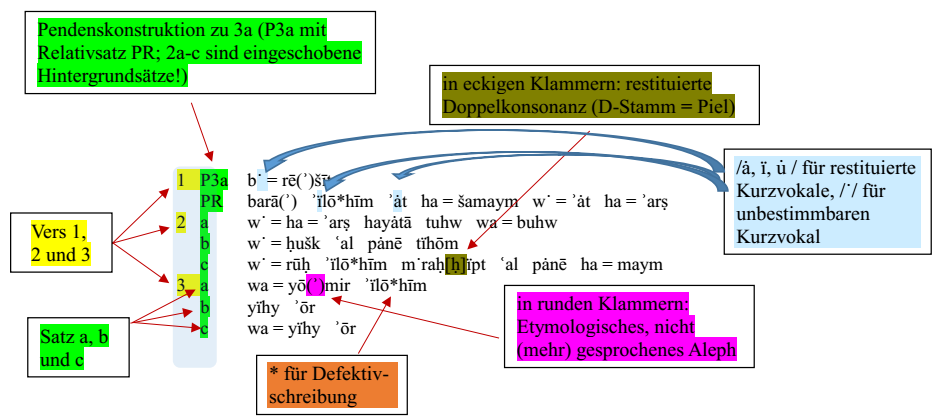
Zur Doppelkonsonanz und zu restituierten Vokalen vgl. näher http://www.bht.gwi.uni-muenchen.de/2-1-morphologische-besonderheiten/
Zum Aleph nach Vokal und zu Plene- und Defektivschreibung vgl. näher http://www.bht.gwi.uni-muenchen.de/2-2-orthographiebezogene-besonderheiten/
Zu den Satzbezeichnungen vgl. näher http://www.bht.gwi.uni-muenchen.de/3-marginalzeichen/
Hannes Neitzke bietet in zwei Dokumenten einen ersten Zugang zur Transkription und zur syntaktischen Gliederung:
Ein erster Zugang
Vom Masoretischen Text zur BHt in 16 Schritten
Klickt man nun auf eine morphologische Einheit ("Token"), etwa die letzte Form in der zweiten Zeile (1PR) ʾarṣ, so gelangt man zu den entsprechenden morphologischen Analysen der Wortebene:

Unterhalb des Analyseeintrags zeigt sich folgendes Bild:

Klickt man auf Wortfügungsebene, so wird ggf. der Syntaxbaum angezeigt, der das Token enthält:
 interpretiert bestehend aus zwei Präpositionalverbindungen (PV), die zweite mit Konjunktion angeschlossen, deshalb „Konjunktionssyndes-e“ (KONJS) aus Konjunktion und PV. Die Präpositionalverbindung wiederum jeweils aus Präposition (Nota objecti gilt bei Richter als Präposition!) und Arti-kelverbindung.
Einzelheiten zur Methodik und zur Terminologie im Kapitel 3.")
Klickt man auf Satzebene, so erscheint folgendes Bild (ohne die Farbmarkierungen):

Im Klammerausdruck (0 9) zur Stellenangabe wird das Intervall und damit auch die Anzahl der morphologischen Einheiten (Tokens) notiert, vgl. auch Zeile "Tokens":
Es handelt sich um 9 Tokens:
- Position (0 1): %b%a%r$a%(%@%) [=barā(ʾ)]
- Position (1 2): %@$I%l$o%*%h$i%m [= ʾїlō*hīm]
- ...
- Position (8 9): %@%a%r$v [= ʾarṣ]
(% und $ sind Steuerzeichen; z.B. %a = a; $a = ā; $A = ȧ; im Einzelnen vgl. https://www.bht.gwi.uni-muenchen.de/db_views/zeichenkodierungtra/).
Die zweite Zeile notiert die Satzart, hier V(erbalsatz), u.z. mit dem Bauplan 4,1. Diese Ziffernangabe steht für folgende Syntagmen: Prädikat P, Subjekt 1 [= 1. Syntagma] und direktes Objekt 2 [= 2.Syntagma]. In der Syntagmenzeile wird auch Position und Umfang der Syntagmen bestimmt von 0-1 findet sich das Prädikat, von 1-2 das Subjekt, von 2-9 das Objekt, welches somit aus 7 Token besteht. Zu Satzbauplänen (wie z.B. V4,1) und Syntagmen (wie P, 1, 2 etc.) vgl. Anhang 4.
Die (Syntagma-)Relationen enthalten Angaben zur Semantik: fac,prod notiert, Aktionsverb, näherhin Vernum des Herstellens, Hervorbringens, d.h. mit effizierten, nicht affiziertem Objekt, po die einleitende nota objecti ʾȧt, konkr,lok-nat+, dass es sich bei šamaym um ein Natur-Ortskonkretum handelt, das Pluszeichen die Mehrgliedrigkeit des Syntagmas (hier: ʾȧt ha = šamaym w˙ = ʾȧt ha = ʾarṣ). Zum ergativem Subjekt wird angeben: Divinum, u.z. rein formal indeterminiert (idet), wegen der Verwendung als (Quasi-)Gottesnamen sekundär (deswegen das >-Zeichen) determiniert.
Es liegt keine Kernsatzerweiterung vor, es finden sich also keine Konjunktionen, Modalwörter o.ä., genauso fehlen satzhafte Erweiterungen (z.B. Interjektionen, Vokative). Die beiden achtstelligen Ziffernblöcke zeigen dementsprechend ausschließlich die Ziffer 0.
Auch die Zeile „Tiefenstruktur“ (wichtig z.B. bei Passivsätzen) ist hier Beispiel ohne Eintrag.
Einzelheiten im Kapitel 4.
Für die Suche ist das Dropdow-Menü von besonderer Bedeutung. Klickt man z.B. in das Suchfeld zu Person/Status (noch ohne irgendetwas einzugeben), so erscheint zur Auswahl, 0, 1, 2, 3, A, C, im Suchfeld zu Genus, 0, M, F, etc. Hier eine Query mit 6 Bedingungen:
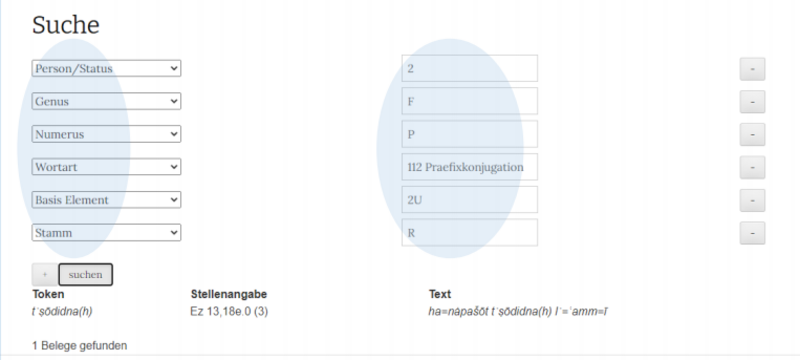
Gesucht wird eine Form der 2. Person, Feminin, Plural, Präfixkonjugation (=112), Wurzelklasse Med. voc. ū (= 2U), Reduplikationsstamm. Das Ergebnis ist genau ein Beleg. Gibt man nach und nach die Suchbedingungen ein, so erscheint im Menu nur noch eine begrenzte Auswahl, etwa für die letzte Bedingung Stamm nur noch G, H, R, weil z.B. D-Stamm in der gesuchten Konstellation nicht belegt ist. Das Menü ist zugleich eine Übersicht über die von Richter angesetzten Werte.
Wichtig ist für die Suche sind auch noch folgende Punkte:
- es sind keine Platzhalter / wildcarts möglich
- bei Suchfeldern mit virtueller Tastatur muss diese benutzt werden
- bei Kombinationen verschiedener Felder erfolgt eine „UND-Abfrage“ (obiges Beispiel)
- bei Kombination gleicher Felder erfolgt eine „ODER-Abfrage“
Einzelheiten und Beispiele im Kapitel 5.
Fußnoten
1 Zur Genese und Verarbeitung der Daten vgl. Riepl (2016) 295-311.
2 Nach den Geniza-Manuskripten (Näheres im Anhang 1)
3 Es geht wohlgemerkt nicht um den Versuch, eine historische aussprache abzubilden, vgl. im Einzelnen: http://www.bht.gwi.uni-muenchen.de/1-1-vollstaendige-wiedergabe-der-morphologischen-struktur-der-worter-im-at/.
